ICPC2023 アジア横浜大会 優勝記
2023 年度のアジア横浜大会に Speed Star で参加してきました。自分は非早生まれの M1 の代なので、今年が参加権のある最後の大会でした。 ICPC は参加し始めて 5 年目、やはり一度は WF に出たいという気持ちが強かったので、今回の横浜にはかなり気合を入れて臨んでいました。 結果として優勝できたのは本当に嬉しかったです。念願の WF(のはず) なので頑張りたい。
チームについて
去年までは KOMOREBI という同級生のチームで 4 年間出続けていましたが、チームメイトが段々競プロに割ける時間が少なくなってきたことと、一度は他の人とも組んでみたい気持ちもあったなど様々な事情から解散。本当はこのチームでも WF に行きたかったです。 新しいチームメイトとして元々目をつけていたのは SSRS だったので、まず初めに誘いました。SSRS に OK して貰えたのはよかったものの、そこからの 3 人目のチームメイト探しはかなり難航。というのも、東大の橙以上は大体が既にチームを所属が近い人達で組んでいて、余っている選手がほぼいませんでした。そのため、今年の初めの半年弱は SSRS と二人チームで Universal Cup 等の 5h コンテストに参加していました。
SSRS の競プロer としての特徴は、かなり多くのバチャやコンテストなどで見てきていたのでよく知っているつもりだった(大体自分と同じ早解き特化タイプで、自分よりかは高難度の典型・デが得意)のですが、実際にチームとして参加してみると思っていたより自分と得意はばらけていて、相性は悪くないんじゃないかな~的なことを思っていました。このあたりで多分チームに足りないのは(変な設定の問題が得意なタイプの)天才型かな、と認識していた気がします。
紆余曲折あって、そろそろメンバーを決めないといけないということで 5 月頃にツイッターで募集。DM してくれた Segtree が - (当時は黄色だったけど)橙 - 俺は高校の後輩で知ってる - SSRS とも JOI で交流がある - 得意は被らなさそう ということで三人目として誘いました。
この辺りから大体の担当は
noimi: 簡単-中盤枠、数え上げ、DP SSRS: 簡単-中盤枠、(数式弄るタイプの FPS 含む)数学、デ、典型、その他面倒枠(幾何とか) segtree: 構築、設定がキモい問題、インタラクティブ
みたいな感じでやっていた気がします。ただ noimi も SSRS も中難度までは割と万遍なく解くタイプで、かつ(コピペ検索アリなら)実装スピードもあまり変わらないということで、前半は解けた方から適当にやっていました。
練習としては UC, nowcoder で十分演習回数が足りていたのでその他は特に行いませんでした。
このチームはオンラインで 5h に出るときに問題概要を一読目で解けた問題以外は完全に discord に(最初から)書くという少し稀有な気がする作戦を取っていました。
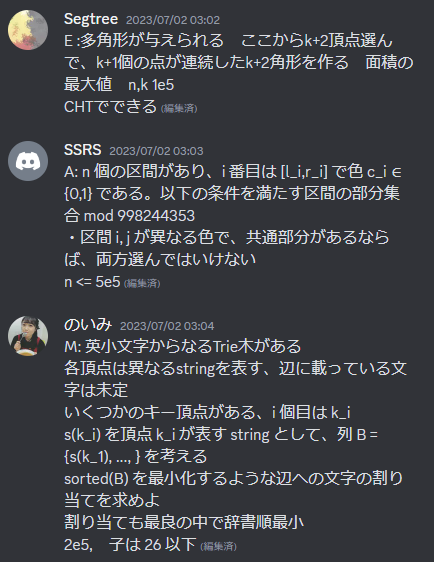
これをしていた辺りから、SSRS の問題文読解速度の異常な速さがチーム内で話題になっていました。 自分も今まで累計で 10 回以上は CF div2-A の FA が取れたくらい英語問題文の斜め読み+早解きには自信があったのですが、前にオフサイトで練習したときに同時に読んでみたところ俺より読むのが 3 倍は速くて完全に自信が破壊されました。
国内予選
まあ何しても通るだろと高をくくっていました。記憶があんまり定かではないんですが、確か BDE と SSRS と協力して G を解いたような気がする。 H が通されなかったことで優勝。 元々このチームは完数勝負にならない限りペナで国内チームに負けることはほぼないだろうなと思っていたので、予想通りの結果になって多少安心していました。
day -1 day 0
学部の頃入っていたサークルの駒場祭出店を手伝っていました。day 0 で OBOG と飲みに行ったら予想以上に飲む羽目になってしまい、1 時に帰宅して風呂で 3 時まで爆睡した上に翌日 6 時に起きて駒場に行ったので最悪でした。まあ前日なんて多少眠い方が本番前に寝れないなんてことがないからいっか!とか適当なことを思っていました。
day 1
駒場祭に行って、大学のトイレで嘔吐してから横浜に向かいました。この辺りのことは始まる前/負けた後に言ったらクソダサいかな~と思って言ってなかったのですが、勝ったから言えるぜ!でも割と体調は良かった気がします。
アジア予選前はある程度作戦を組んでいました。1 週間前くらいまでは、SSRS が JAG 夏合宿で一人でも序盤他チームに勝っていたことを考えると、マクロも要らないし一人で AB やらせてその間に他の問題を二人が読む、という作戦でいました。
ただ、本番の数日前に
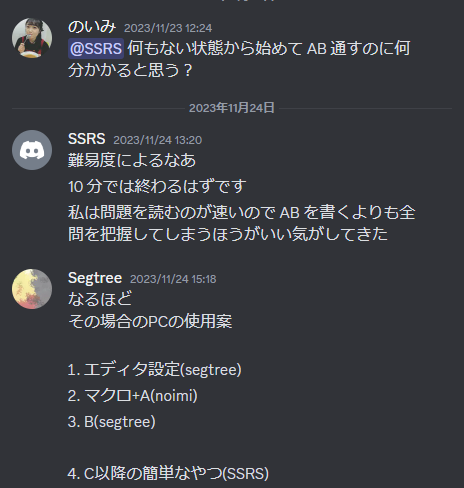

という会話をし、納得したのでこの作戦に切り替えることにしました。確かに、UC 等の強いチームが多く出るコンテストでは、序盤から順位表情報が充実していて難易度が推定しやすいのですが、アジア予選の参加チームはそれに比べると強いチームは少ない上、上位のチームも早解き型ではないということで問題を先に把握する効用は確かに大きいと思いました。
リハーサル中に作戦の方向性を決め、いくつかの細かい取り決めを行いました。例えば、
- SSRS が先に読んだ問題で読んだ瞬間に解けた問題が 2 問(X, Y) があった。どちらも自信があるが Y の方が明らかに知識/既出 driven で解けた問題であり、難しい。こういう場合は多少実装が遅くなっても先に Y を通してしまって他チームに非適切な情報を与えてしまった方が良いので Y から書く。
等です。
実際に決まったスタートの作戦は
SSRS: C 以降を読む segtree: PC のセットアップ→B もしくは SSRS から考察するべき問題を貰う noimi: PC のセットアップ中に A, B を解いてそのまま書き始める
というものでした。まあ B は解けなかったわけですが…
実際、序盤なんて一人でもいいと思うので、SSRS の役目を二人で担ってでも最初期に問題を把握するメリットは大きいんじゃないかなと思います。
チームの席が一番後ろだったので色々な知っている JAG スタッフの顔が見えました。知っている人に手を振ったり、ダル絡みしたりしていたんですが、非交流通知が出されていたみたいで、余り乗ってくれなくて悲しかったです。ちなみに JAG の人は、ツイッターが露悪的であればあるほど英語やだな~って顔で日本語で話しかけると日本語で回答してくれがちという法則を発見しました!
帰りの電車で SSRS とどうしたら tonosama に勝てるかな~という話をしていました。まあ問題セット次第なのはそれはそうで、難問枠が典型寄り/実装寄りだったりするか、簡単目のセットで全完(or 0 AC を除いた問題の速度)勝負だったりしたら勝てそうだが、AGC 的なパズルが出たらキツそうという話をしていました。
day 2 本番
コンテスト当日まで「東大チームに負けなくて 2 位以内なら WF はほぼ確」だと思っていたので、当日に tatyam から 1 位以外のチームは playoff 送りと聞いてひっくり返っていました。対 tonosama の勝ち負けはおまけだと思ってたのに… このことで、前日までは「まあ他の東大チームに負けなければいい」くらいの気持ちだったのが、「優勝しなければ…」という心構えに急に変わりました。 全然関係ないんですが、朝寝ぐせがヤバくて闘ってたら普通に遅刻しかけて悲しかったです。まさか入場最後とは…
本番はこんな感じでした (https://segtree.hatenablog.com/entry/2023/11/27/011031) で済まそうかなと思ったのですが、折角なので自分視点の動きも書いておくことにします。
(0:05 くらい) Segtree が PC 設定諸々終わる
この間に A は完全に解けていて、B の読解が中途半端みたいな感じでした。条件式がかかれていたので、そっちから理解しようとしたら案外変数が多かったのと割と解釈しずらい式で迷走してしまいました。 とりあえず PC を受け取って A を実装することにする。まあ DP かなとか思いつつ、DP 書くなら…と思ってマクロを一部書いてから実装することにした。
A AC(0:08)
このままパソコンの前で B を読んでる間に SSRS が全部読めた、F はすぐ書けるというのでパソコンを渡す。その間に何故か B の解釈が自分の中で入れ替わってて「あれ毎回長さ c のやつだけ見れば良くね?」みたいな謎の嘘で行けると思い込み始める。このタイミングで segtree は D が詰めれば終わると言われて渡されていた。
F AC(0:12)
SSRS が返ってきたので ↑ の B を書いたところ、書いている途中で大嘘に気づく。SSRS を呼び寄せて長さが c とは限らないんだよね~と相談開始したらすぐに変数分離じゃね?と言われてわからなかった自分を罵倒する。セグ木があれば一発ということがわかり、セグ木を写経するなら俺より速いということでパス。この間に segtree と D の確認をする。
概要と中身をさっと聞き、まああってそうだけど文字列の一致判定とか怠くね?みたいな話をするが、なんか行けるらしいのでそのまま任せて簡単と言われた H を読む。フローっぽいとだけ伝えられた。
順序と分割と二つのステップがあるのが怠いが、順序はいつものなのですぐわかる。順序を調べるときに書くいつもの式
を書いていたので、流れでΣをバラシて二点間の関係に落とすと後は燃やす埋めるそのまま。ここら辺のどっかで B が通る
B AC(0:25) segtree が D を書き始める。まあ H は Dinic 書かないといけないしパソコン貰えそうになってから細かい部分詰めるか、という気持ちになって一旦他の問題の概要を聞くことにした。 このタイミングで、SSRS が C, E, I : ムズそう J: 難しくなかったとしても面倒そう K: 謎 G: 中 みたいな評価が下していて、すぐに解けそうな問題はなかったので一旦 998 を中心に概要を大体聞いた。流石にそろそろ順位表を見ようと思い、見たところ E が tonosama にかなり速く解かれていたので E を考えることにする。確かこのタイミングで負けてて軽く萎えたような覚えがある。 D が少し燃えかけていたので H を実装に移る準備をしつつ解法を SSRS に聞いてもらい、一緒に辺の貼り方を考えてもらう(いつも Luzhiled's memo に頼り切りのため…)。初心に戻って普通に最小カットの方で解釈したら合ってそうだったので、D を印刷してもらってパソコンを貰う。Dinic を写経したりしてるうちに D のバグが分かってそうだったので、何回かパソコンの受け渡しをしつつ実装を進める。確かこの間に E が解けた気がする。通すまでが速い→変な解法じゃない ということで多項式がすぐ見えて、O(M2N) を O(N 2N) に落とすのも、自分はこういったタイプの高速化が得意なので特に苦労せず出た。このタイミングで G も解けていた。
なんやかんやあって
D AC(0:53) H AC(0:57)
G もそこまで実装にかからなさそうだった上、E を詰めてから書き始めたかったので、まず SSRS に PC を渡す。バグった辺りで E が一瞬で書けることを主張して、印刷デバッグをしてもらっている間に E を AC。 この辺りで脳が起きてきて実装も早くなってきた気がする。
E AC(1:10)
無事にバグもその間に見つかり、すぐ修正出来ていた。
G AC(1:14)
E を解き終わった後にその後のムーブを考えた。 残りが C, I, J, K の 4 問で AC が出ているのが K 1 チームというとても動きづらい状況だった。 その段階での問題の評価が、
C: 回転がなかったらラグ反のアレで解けている、Polya を使えば解けそうだけど 2 周期以上の時も毎回取り切るは嘘 I: 幾何っぽいが進展は無 J: 差分が凸なのでそれを管理するタイプのマージテク木 DP っぽい K: インタラクティブで幾何だから嫌だけど、AC 出てるしそこまで難しくなさそう
ということで並行目に考えることにした。 segtree, SSRS: K noimi: C, J
の具合だったはず。C を少し考えたら 2 周期の時は回文が残ることが必要十分であることが分かり、まあどうせ 3 以上でもそうだろみたいなところまでわかったが、肝心の回文は長さごとに求める必要がありそうで困る。 J も DP は一気にマージする必要がありそうで、デカいところに一回ずつマージしていくみたいなことが出来ずに困る。(今見ている頂点で何回使ったかの情報もマージする過程では必要になるので) ただ下凸にはなるし流石にそういう系だろ…で固まる。
この間で K は解けそうという話になり、時間もあったので一旦全員で K を考える。SSRS が算数で出来ると主張しだしたが、ぼくは中学数学の式を見たくなかったので「信じるので一人で書いてください」みたいなことを言って丸投げした。
その間に J を考えていたが、台湾のチームが解いていることに気づく。実は Day 1 で確認していたのだが、台湾のチームは国内予選?で逆から見ると Incremental Bridge Connectivity になるだけの問題を解いていなかったので、そこが解いているということは凸性を保つタイプのマージとかではないんじゃないか…?と薄っすら思い始める。 配置できる必要十分な個数条件は有名なので、そっちを fix する方向で考えるとそれっぽい貪欲が思い浮かぶ。適当なケースとタイブレークを考えてみると、交換によって上手く回りそうなことをなんとなく確認したので segtree にも聞いてもらって一回書いてみようということになった。
K AC(1:47)
J は lazy segtree + HLD が必要だったので、上目遣いで SSRS を見つめて弱音を吐くことで代わりにそこを実装してもらうことに成功。空で書いててすげーとなった。この間に残り二人で I を考える。自分的には arg sort した後に両側累積ベクトル和を取った凸多角形について考えることが筋がよさそうだと思ったが、segtree は濃度で考えた方が分かりやすそうだとなったので、個人個人で考えることに。 自分の方針は実際には writer と同じだったのだが、完成形も同様に凸多角形で考えることが何故か思い浮かばず、そちら側は点で処理してしまっていたため解けなかった。
しばらくすると HLD が書き終わったので、受け取って書き始める。 アルゴリズムの中身自体は単純だが、軽くバグってしまった。HLD と main のどっちがバグってるかもわからなかったので SSRS とデバッグする。結果的には両方バグってて最悪だった。多少時間をかけたものの、そこまで炎上はせずに無事 1 発 AC。この問題はランダムテストを書くことを覚悟していたので、書かずに済んでよかった。そういえば結局一回も書かなかったな…
J AC(2:13)
segtree が I が多分解けたというので話を聞く。累積和で判定できると聞いて、まあ確かに arg 小さい方から使うべきだし微調整は出来るからあってそうという気持ちになった。SSRS は疑っていたが、まあ時間もあるしそれならすぐ実装できそうだからと思い、自分が書くことになった。二人に後ろから見てもらいながら書いていたが、自分が考えたわけではない解法の実装はあまり上手く行かないなと感じた。普段だったら「薄い方と濃い方で両方やるから最初から 2 回解くことを前提に~」みたいなことを考えるが、そのときは何も工夫せずにそのまま書いてしまった。 途中で SSRS に繰り返しは同じところで処理した方がいいのでは?a, b と c, d を swap すれば出来ると言われたのでそれでやった。そもそも a, b, c, d じゃなくて a[0], b[0], a[1], b[1] にするべきなんだよな~~~~ まあ何はともあれ書き終わり多少のバグを取って AC。
I AC(2:34)
解法が多少は不安だったので通って嬉しかった。グータッチをする。 ここで順位表を見て 2 位とかなりの差をつけた 10 完であることを確認した。C もかなりの進捗はある上に、2時間半あるなら多分通るだろと思っていた。ペナ差で負けることは無さそうだったので、落ち着いて C を解くことに。 まず全員に考察を共有して考え始める。回文と偶奇性について色々わかりはじめ、SSRS がカタラン数の K 乗の例の母関数を持ち込んでいたので(神!)具体的な式も立ち始める。結構複雑になりそうだったので、modint を segtree に写経してもらう。二人で落ち着いて 2 乗の式を立てて、サンプルを試すことにした。一発では合わなかったが、色々な箇所を直していくと無事サンプルがあった。ここからは計算量を落とすことに。
括弧列に直した後に、累積和の差が 0 に着地する回数と回文の長さで 2 乗の式を立てていたが、どちらを固定しても指数部分や分数部分が邪魔になって上手く式をまとめられないという話になったが、SSRS が畳み込みの式になることを指摘し、丁寧丁寧丁寧に式を変形、変形する度にコードも変えてサンプルを試し…とすることで無事畳み込みの式が出来た。 畳み込みを写経し、実装してみると(一回畳み込みの写経をミスったが)無事サンプルが合う。ただ、TL がかなり不安だったので 3e6 で一回手元で試すことにした。試したところ 0.8sec 程度で流石に通るだろ!と思いながら DOM judge を開いたところ 3:59:52 とかでめちゃくちゃ焦る。凍結前間に合わせてぇ~~~と言いながら急いで操作するものの、流石に間に合わず、提出が 4:00:03 に。手元で時間を見ていたことを少し後悔。
ジャッジにはめちゃくちゃ時間がかかっていたので、手元で約数の和がもっとも大きい数を探してみることにした。 こんなコードを書いた。
vector<int> d(3e6 + 1); rep(i, 1, si(d)) { for(int j = 0; j += i; j <= 3e6) d[j] += i; }
と書いていたら SSRS に「逆!逆!」と言われる。あー j と i どこか逆になったか?と思い見てみるが、合ってそうなので「え、いや合ってね?何が?」と聞いたら「for 文の順番です」と言われる。 見てみると自分が灰色以下であることが分かった。マクロに頼ってると for 文が書けなくなるんですよね~~~いや、流石に恥ずかしい。
そんなこんなしていたら C が通ったので喜ぶ。(あんまり嬉しそうにすると全完したのが分かってしまって他のチームに悪いかも、ということで予め喜びは抑えることに決めていた。) for 文が書けなかった恥ずかしさも吹き飛ぶ。
理論的にペナ差が逆転不可能であることを確認してから、残りの 1 時間は復習をしたり、弁当を食べたりしていた。この 1 時間で喜びも少しずつ収まってしまった。
振り返り
後でもう少し詳しく書く。
東大の他の 2 チームは全員が自分と同学年で、色々思うところはあったので、仮に自分達が優勝して引導を渡してしまうなら「あのペナがなければ…」みたいな差ではなく、断トツで勝ちたいという気持ちがあったので、その点は軽く安心していた。
終わった後にTwitterの当時の TL を見てみたら、案の定凍結直後提出についていろいろ言われていた。「こういうことしそうなチームではないが、流石にこれは偶々とは思えないのでのいみが考えたしかありえない。悪い顔をして提出している様が目に浮かぶ。最低なやつだ。」(意訳)みたいなことを言われていてゲラゲラ笑っていました、嘘です泣きました。 SSRS は終わった後やばい!天才!みたいに褒められていたのに、俺は性格の悪そうさについてのみ言及されていて悲しい。 hitonanode さんにその話をしたら「普段の行いですね😁」と言われた。そ、そんな…
まあ、おかげ様でこのコピペ検索禁止の時代遅れクソコンテストにもうしばらく出られることになったので、まだまだ頑張っていこうと思います。5h で対戦する皆さまよろしくお願いします。
Distance Sum (AOJ2636)
この記事は帰ってきた AOJ-ICPC Advent Calendar 2022 17 日目の記事です。
木クエリゴリゴリ問題です。
問題概要
頂点の木がある。頂点
の親は
であり、その間の距離は
である。
について、
を求めよ。
制約
解法
大体重心を求めたいという問題です。 頂点のうち、
頂点しか気にならないのでそれらからなる圧縮木を作ってみます。すると、重心の性質から求める
はその圧縮木上の頂点としてよいことが分かります。(特に、
が簡単にわかる。)
さて、重心はある頂点から部分木のサイズが 以上の方向に移動することを繰り返すことで求まる。また、圧縮木上でも普通の木と変わらず、移動すると必ず部分木のサイズが 1 以上減る(不変だとすると、その頂点は圧縮木に不必要)
このことから、圧縮木の頂点を一つ増やしたとき、重心は高々一回移動するのみである。移動した際の答えの変化はセグ木等で適当に求まるので、圧縮木を動的に変化させることを考える。
圧縮木は、オイラーツアー順に頂点を見たときに隣合った頂点の LCA を全て追加することで求まる。
そのため、新しい頂点を追加する際に既にみた頂点のうちオイラーツアー順で隣接しているものとの LCA が追加する頂点の候補である。
今、頂点 を追加するとき、オイラーツアー順で手前の頂点を
とし、
とする。
が圧縮木に含まれていないとき、
の元々の(圧縮木上での)親を
とし、
と結びなおす。
これをオイラーツアー順で次に隣接している頂点
についても行う。
の親は
に対する
のうち、深い方である。
が圧縮木上にまだないことから、
の子供は高々一つしかない。よって、
と子供を結ぶ辺、
と親を結ぶ辺が正しく貼れる。
さて、この圧縮木をどう管理するかだが、HLD と map を用いてグラフを管理することが出来る。圧縮木上で の辺を貼る際、
から
に向かって 1 進んだ頂点を
とし、
G[U][W] = V として管理すればよい。後は頑張るとなんとかなる。
この持ち方をしていれば、「辺を切る」という操作は必要なくなるので楽(辺を切る際、必ず新しいところと結ぶため)
実装
#include <bits/stdc++.h> using namespace std; #define ov3(a, b, c, name, ...) name #define ll long long #define rep2(i, a, b) for(ll i = (a); i < (b); i++) #define rep1(i, n) rep2(i, 0, n) #define rep0(n) rep1(iiiii, n) #define rep(...) ov3(__VA_ARGS__, rep2, rep1, rep0)(__VA_ARGS__) #define si(c) (ll)(c.size()) #define pll pair<ll, ll> #define vl vector<ll> #define all(v) v.begin(), v.end() #define fore(e, v) for(auto &&e : v) template <typename S, typename T> bool chmax(S &x, const T &y) { return (x < y ? x = y, true : false); } template <typename S, typename T> bool chmin(S &x, const T &y) { return (x > y ? x = y, true : false); } template <typename T> ostream &operator<<(ostream &os, const vector<T> &v) { os << "{"; rep(i, si(v)) { if(i) os << ", "; os << v[i]; } return os << "}"; } template <typename T, typename F> struct segtree { int n, rn; vector<T> seg; F f; T id; segtree() = default; segtree(int rn, F f, T id) : rn(rn), f(f), id(id) { n = 1; while(n < rn) n <<= 1; seg.assign(n * 2, id); } void set(int i, T x) { seg[i + n] = x; } void build() { for(int k = n - 1; k > 0; k--) seg[k] = f(seg[k * 2], seg[k * 2 + 1]); } void update(int i, T x) { set(i, x); i += n; while(i >>= 1) seg[i] = f(seg[i * 2], seg[i * 2 + 1]); } T get(int i) { return seg[i + n]; } T prod(int l, int r) { T L = id, R = id; for(l += n, r += n; l < r; l >>= 1, r >>= 1) { if(l & 1) L = f(L, seg[l++]); if(r & 1) R = f(seg[--r], R); } return f(L, R); } template <typename C> int max_right(int l, const C &c) { assert(c(id)); if(l >= rn) return rn; l += n; T sum = id; do { while((l & 1) == 0) l >>= 1; if(!c(f(sum, seg[l]))) { while(l < n) { l <<= 1; auto nxt = f(sum, seg[l]); if(c(nxt)) { sum = nxt; l++; } } return l - n; } sum = f(sum, seg[l++]); } while((l & -l) != l); return rn; } }; template <typename G> struct HLD { int n; G &g; vector<int> sub, in, out, head, rev, par, d; HLD(G &g) : n(si(g)), g(g), sub(n), in(n), out(n), head(n), rev(n), par(n), d(n) {} void dfs1(int x, int p) { par[x] = p; sub[x] = 1; if(g[x].size() and g[x][0] == p) swap(g[x][0], g[x].back()); fore(e, g[x]) { if(e == p) continue; d[e] = d[x] + 1; dfs1(e, x); sub[x] += sub[e]; if(sub[g[x][0]] < sub[e]) swap(g[x][0], e); } } void dfs2(int x, int p, int &t) { in[x] = t++; rev[in[x]] = x; fore(e, g[x]) { if(e == p) continue; head[e] = (g[x][0] == e ? head[x] : e); dfs2(e, x, t); } out[x] = t; } void build() { int t = 0; head[0] = 0; dfs1(0, -1); dfs2(0, -1, t); } int la(int v, int k) { while(1) { int u = head[v]; if(in[v] - k >= in[u]) return rev[in[v] - k]; k -= in[v] - in[u] + 1; v = par[u]; } } int lca(int u, int v) { for(;; v = par[head[v]]) { if(in[u] > in[v]) swap(u, v); if(head[u] == head[v]) return u; } } template <typename T, typename Q, typename F> T query(int u, int v, const T &e, const Q &q, const F &f, bool edge = false) { T l = e, r = e; for(;; v = par[head[v]]) { if(in[u] > in[v]) swap(u, v), swap(l, r); if(head[u] == head[v]) break; l = f(q(in[head[v]], in[v] + 1), l); } return f(f(q(in[u] + edge, in[v] + 1), l), r); } int dist(int u, int v) { return d[u] + d[v] - 2 * d[lca(u, v)]; } int jump(int s, int t, int i) { if(!i) return s; int l = lca(s, t); int dst = d[s] + d[t] - d[l] * 2; if(dst < i) return -1; if(d[s] - d[l] >= i) return la(s, i); i -= d[s] - d[l]; return la(t, d[t] - d[l] - i); } }; template <typename T> struct edge { int to; T cost; edge(int to, T cost) : to(to), cost(cost) {} edge &operator=(const int &x) { to = x; return *this; } operator int() const { return to; } }; int main() { cin.tie(0), cout.tie(0); ios::sync_with_stdio(false); int n; cin >> n; vector<vector<edge<ll>>> g(n); rep(i, 1, n) { int x, c; cin >> x >> c; x--; g[x].emplace_back(i, c); } HLD hld(g); hld.build(); ll sum = 0; int now = 0; cout << sum << "\n"; vector<map<int, int>> G(n); set<int> s; s.emplace(0); vl par(n); auto connect = [&](int i, int j) { if(i == j) return; if(hld.d[i] < hld.d[j]) swap(i, j); par[i] = j; G[i][hld.jump(i, j, 1)] = j; G[j][hld.jump(j, i, 1)] = i; }; vl d(n), dp(n); auto dfs = [&](auto &&f, int x) -> void { fore(e, g[x]) { d[e] = d[x] + e.cost; dp[e] = e.cost; f(f, e); } }; dfs(dfs, 0); auto dist = [&](int i, int j) { int u = hld.lca(i, j); return d[i] + d[j] - d[u] * 2; }; auto f = [](int x, int y) { return x + y; }; segtree<int, decltype(f)> seg(n, f, 0); seg.update(0, 1); rep(i, 1, n) { int idx = hld.in[i]; auto it = s.lower_bound(idx); int mypar; if(it != begin(s)) { int l = hld.rev[*prev(it)]; int c = hld.lca(l, i); mypar = c; if(s.insert(hld.in[c]).second) { l = hld.rev[*s.lower_bound(hld.in[hld.jump(c, l, 1)])]; int p = par[l]; connect(l, c); connect(i, c); connect(c, p); } } if(it != end(s)) { int r = hld.rev[*it]; int c = hld.lca(r, i); if(hld.d[mypar] < hld.d[c]) mypar = c; if(s.insert(hld.in[c]).second) { r = hld.rev[*s.lower_bound(hld.in[hld.jump(c, r, 1)])]; int p = par[r]; connect(r, c); connect(i, c); connect(c, p); } } connect(i, mypar); s.insert(hld.in[i]); seg.update(hld.in[i], 1); sum += dist(now, i); int cnt = 0; while(true) { if(now == i) break; int nxt = hld.jump(now, i, 1); int to = G[now][nxt]; ll s; if(hld.d[nxt] > hld.d[now]) { s = seg.prod(hld.in[to], hld.out[to]); } else s = (i + 1) - seg.prod(hld.in[now], hld.out[now]); if(s > (i + 1 - s)) { sum -= dist(now, to) * (s * 2 - (i + 1)); now = to; } else { break; } } cout << sum << '\n'; } }
優秀なプログラマになるには (AOJ1631)
この記事は帰ってきた AOJ-ICPC Advent Calendar 2022 10 日目の記事です。
少し珍しいタイプの木DPの問題です。
問題概要
頂点の木がある。頂点
の親は
である。各頂点
には価値
のコインが
枚ある。
あなたは木から価値の合計が最大になるよう最大
枚のコインを回収したい。ただし、頂点
のコインを 1 枚以上回収するためには、
のコインを
枚以上回収していなければならない。
条件を満たすようにコインを回収するとき、価値の合計の最大値はいくつか。
制約
解法
問題設定と制約から、まずは単純な木 DP(dp[i][j] := (i 以下の部分木で j 枚回収するときの最大値)) を考えてしまった。しかし、これはなかなか筋が悪いことがわかる。
というのも、この問題の肝の設定である。( のコインを
枚以上回収していなければならない。) という条件に相性が悪い。この条件を上手く省けるような DP を設計したい。
条件を活かすためには、下からではなく上から dfs 順に見るいわゆるトップダウンの木 DP を考えると、今訪問している頂点までの条件を満たしていることが確定しているので、一見相性がよさそうに見える。 しかし、このパターンでは先祖でも子孫でもない頂点の情報が完全に抜け落ちてしまっているため、DP するのは難しそうに見える。
この情報は、実は DP する順番を上手く定めることで保持することが出来る。 トップダウンの木 DP では、DP テーブルを参照として持たせながら dfs をするパターンと、更新を子以外も含めることで上手く行う二つのパターンが存在する。 今回は後者を用いて実装した。(前者の方がわかりやすいが、この問題は定数倍がきつかったのでやむなく)
子以外を含めるというのは、例えばある葉に到達したときに、その葉をもとに更新する dp テーブルを dfs 順で次のノードにするということである。 こうすることで、全ての頂点を訪問した情報を得ることが出来る。
さて、情報が抜け落ちてしまうという問題に戻ろう。
直接の子供以外に遷移するとき、それは先祖の兄弟の関係にあるノードである。もしこのノードの の値が既に訪問している兄弟ノードの
よりも小さければ、条件は無視できる。
この考察がこの問題の本質である。
よって、条件は無視できるので単に更新することが出来る。
更新は以下のようにして行われる。
頂点  を見ているとき
を見ているとき
子供 に対して、dp[v] を dp[x] から
枚以上
枚以下を回収した上で更新。
先祖の兄弟
に対して、dp[v] を dp[x] から
枚以上
枚以下を回収した上で更新。
どの子供にも遷移しない場合があるので、葉以外の頂点からも dfs 順で最も近い先祖の弟に遷移させなければならないことに注意する(ぼくはこれに気づかなくて死んでました)
この更新、パッと見では に見えるが、実はこれは簡単に
に落とすことが出来る。
dp[v][i] =
これはスライド最小値で計算できる。
実装
#ifdef noimi #include <stdc++.h> #else #include <bits/stdc++.h> #endif #define ll long long #define REP0(n) for(ll iiii = 0; iiii < (n); i++) #define REP1(i, n) for(ll i = 0; i < (n); i++) #define REP2(i, a, b) for(ll i = (a); i < (b); i++) #define overload3(a, b, c, name, ...) name #define rep(...) overload3(__VA_ARGS__, REP2, REP1, REP0)(__VA_ARGS__) #define vi vector<int> using namespace std; template <typename T, typename S> bool chmax(T &x, const S &y) { return (x < y ? x = y, true : false); } template <typename T> ostream &operator<<(ostream &os, const vector<T> &v) { os << "{"; rep(i, v.size()) { if(i) os << ", "; os << v[i]; } return os << "}"; } // deque struct DEQUE { int l, r; int d[100100]; DEQUE() : l(0), r(0) {} bool empty() { return l == r; } void push_back(int x) { d[r++] = x; } void pop_back() { r--; } void pop_front() { l++; } void clear() { l = r = 0; } int back() { return d[r - 1]; } int front() { return d[l]; } }; ll dp[101][100010]; int main() { DEQUE d; while(true) { int n, k; cin >> n >> k; if(!n) exit(0); vi h(n); vector<ll> s(n); vector<vi> g(n); rep(i, n) cin >> h[i], h[i] = min(h[i], k); rep(i, n) cin >> s[i]; rep(i, 1, n) { int x; cin >> x; x--; g[x].emplace_back(i); } vi l(n); rep(i, 1, n) cin >> l[i]; constexpr ll inf = 1e18; rep(i, n + 1) rep(j, k + 1) dp[i][j] = -inf; vector<int> idx, nxt(n); { auto dfs = [&](auto &&f, int x, int nv) -> void { idx.emplace_back(x); sort(begin(g[x]), end(g[x]), [&](int i, int j) { return l[i] > l[j]; }); rep(i, g[x].size()) { f(f, g[x][i], (i == g[x].size() - 1 ? nv : g[x][i + 1])); } nxt[x] = nv; }; dfs(dfs, 0, n); } dp[0][0] = 0; auto f = [&](ll *tmp, ll *nxt, ll s, ll L, ll R) { // rep(i, k + 1) tmp[i] -= i * s; d.clear(); rep(i, L, k + 1) { while(!d.empty() and tmp[d.back()] - d.back() * s < tmp[i - L] - (i - L) * s) d.pop_back(); d.push_back(i - L); chmax(nxt[i], tmp[d.front()] - d.front() * s + i * s); if(d.front() == i - R) d.pop_front(); } }; rep(i, n) { int x = idx[i]; for(auto e : g[x]) { int L = l[e], R = h[x]; f(dp[x], dp[e], s[x], L, R); } int e = idx[i + 1]; f(dp[x], dp[nxt[x]], s[x], 0, h[x]); } ll ma = 0; rep(j, k + 1) chmax(ma, dp[n][j]); cout << ma << endl; } }
凸多角形の加法 (AOJ 1639)
この記事は帰ってきた AOJ-ICPC Advent Calendar 2022 3 日目の記事です。
ミンコフスキー和に関しての問題です。
問題概要
凸多角形 と整数
があり、
を満たしている。
凸多角形
が与えられるので、条件を満たす
のうち、
の面積の和の二倍の最小値を求めてください。
ただし + はミンコフスキー和を表す。
解法
まず、ミンコフスキー和は、凸多角形をなす辺を順番に並べて偏角ソートしたものをマージソートすることで求まることが知られています。
このことから、 のうち、
が分かっているとき
を、つまり
を求めることができます。
ここで、 を考えてみましょう。線形性より、
が存在したとすると
が成り立ちます。
このとき、引き算した部分が打ち消し合うことから、
としたとき、
が引き続き成り立ちます。よって、
で問題を考えても答えは等しくなります。
引き算が出来る条件を考えましょう。これはそこまで難しくなく、単に の全ての辺に対して、同じ向きで長さが
のそれ以上であるような辺が
に存在していることです。
引き算する向きは一意に定まります。
このユークリッドの互除法のような操作を繰り返すことで、最終的に引き算が行えなくなったとき、それらが です。
これは、引き算が行えないことと
かつ
(またはその逆) が同値であることと、それに加えて
が同時に成り立つことがないことから言えます。(
となってしまう)
よって、この操作が行えればこの問題が解けたことが分かりました。
計算量については、ユークリッドの互除法と同様に座標が 2 回で半分以下になることから、 です。(引き算をする際、一気に引ける限り引かないと計算量が
になりますが、テストケースが弱いので通ります。(一辺 1 の正方形と、その辺と平行な長さ 10 ^ 6 の辺を含んで頂点数 1000 の図形の組とかがたくさんあると死ぬ)
実装
#include <bits/stdc++.h> using namespace std; #define ll long long #define rep(i, n) for(ll i = 0; i < (n); i++) using P = vector<pair<ll, ll>>; constexpr int type(ll x, ll y) { if(x == 0 and y == 0) return 0; if(y < 0 or (y == 0 and x > 0)) return -1; return 1; } bool arg_cmp(pair<ll, ll> x, pair<ll, ll> y) { int L = type(x.first, x.second), R = type(y.first, y.second); if(L != R) return L < R; ll X = x.first * y.second, Y = y.first * x.second; if(X != Y) return X > Y; return x.first < y.first; } long long solve(P &x, P &y, int second = 0) { bool flag = true; int j = 0; P ny; if(empty(x)) flag = false; for(auto &[a, b] : x) { while(j < y.size()) { auto &[c, d] = y[j]; if(a * d == b * c and abs(a + b) <= abs(c + d)) { break; } ny.emplace_back(c, d); j++; } if(j == y.size()) { flag = false; break; } if(y[j].first - a or y[j].second - b) ny.emplace_back(y[j].first - a, y[j].second - b); j++; } while(j < y.size()) { ny.emplace_back(y[j++]); } if(flag) return solve(x, ny); else if(!second) { return solve(y, x, true); } ll res = 0; auto calc = [&](const P &x) { pair<ll, ll> p{}; rep(i, x.size()) { pair<ll, ll> np(p.first + x[i].first, p.second + x[i].second); res += p.first * np.second - p.second * np.first; p = np; } }; calc(x); calc(y); return res; } int main() { while(true) { int n, m; cin >> n >> m; if(!n) exit(0); auto get = [](int n) { P r(n); rep(i, n) cin >> r[i].first >> r[i].second; P res(n); rep(i, n) res[i] = pair(r[(i + 1) % n].first - r[i].first, r[(i + 1) % n].second - r[i].second); int k = min_element(begin(res), end(res), arg_cmp) - begin(res); rotate(begin(res), begin(res) + k, end(res)); return pair(r, res); }; auto [r, x] = get(n); auto [s, y] = get(m); ll res = solve(x, y); cout << res << endl; } }
Topcoder の greed で std::data との衝突を回避する方法
greed ではテストケースの情報を data という変数に格納していますが、これは C++17 から追加された std::data という関数と衝突してしまってコンパイルが通りません。 次のように変えることで衝突を防げます。
// template class ${ClassName} { public: ${Method.ReturnType} ${Method.Name}(${Method.Params}) { return ${Method.ReturnType;zeroval}; } }; ${CutBegin} namespace test_code { ${<TestCode} } int main() { char *argv[1]; test_code::main(0, argv); } ${CutEnd}
適当な namespace に退避させてあげれば ok です。
Topcoder の greed で std::data との衝突を回避する方法
greed ではテストケースの情報を data という変数に格納していますが、これは C++17 から追加された std::data という関数と衝突してしまってコンパイルが通りません。 次のように変えることで衝突を防げます。
// template class ${ClassName} { public: ${Method.ReturnType} ${Method.Name}(${Method.Params}) { return ${Method.ReturnType;zeroval}; } }; ${CutBegin} namespace test_code { ${<TestCode} } int main() { char *argv[1]; test_code::main(0, argv); } ${CutEnd}
適当な namespace に退避させてあげれば ok です。
Network Reliability (700) AOJ-ICPC 2345 $O(N^2 2^N)$ 解
$ V = \left\{ 1, \ldots, N \right\} $ とする。 $ f(S) = (S \subset V \text{に誘導される部分グラフが連結な確率})$ とおく。
実は $ 1 \in S$ しか考えなくていいことがわかって、連結にならない確率を考えると、1 を含む連結成分で場合分けすればよい。 $ K(U, V)$ を $ U, V$ を結ぶ辺の数とすると、
$$ f(S) = 1 - \sum_{U \subset S, 1 \in U} f(U) p ^ {K\left(U, S - U\right)} $$ となる。
$ X(U)$ を $ U$ に含まれる辺の数とすると、 $ K(U, V) = X(U) + X(V) - X(U \cup V) $ と書けるので、先ほどの式は
$$ f(S) p ^ {-X(S)} = 1 - \sum_{U \subset S, 1 \in U} f(U) p ^ {-X(U)} p ^ {-X(S - U)} $$
と書ける。
\begin{align} F(S) = f(S) p ^ {-X(S)} (1 \in S) \\ G(S) = p ^ {-X(S)} (1 \notin S, S \neq \phi) \\ H(S) = 1 (1 \in S) \end{align}
とすると、
$$ H - F \ast G = F $$
と書けることが分かる $ \ast $ は subset convolution
$I(S)$ を $S = \phi$ のときのみ 1 となる subset convolution の単位元とすると、
$$ H - F \ast G = F \\ H = F \ast G + F \\ H = F \ast (G + I) $$
と変形できる。よって、 $F = H \ast \mathrm{inv}(G + I)$ と求まる。
(subset convolution の inv は zeta 後の各多項式を inv すればいいそうです、Nyaan さんに教えてもらいました。)